
Customer Segmentation at Glovo - Part 1

Introduction to Glovo:
Glovo is a Spanish tech company that provides innovative solutions to connect customers, businesses and couriers to provide delivery services, and it is the fastest-growing multicategory player in Europe, Western Asia and Africa.
Part 1: What is segmentation and why do we need it?
Segmentation was a challenging and interesting project that my colleague and friend Ahmad and I leaded, designed and implemented for our cluster and the whole company. Customer segmentation can be summarized by Wikipedia as: “dividing a broad consumer or business market, normally consisting of existing and potential customers, into sub-groups of consumers (known as segments) based on some type of shared characteristics”. The idea of segmenting the customer base had been around for more than an year at Glovo, with ongoing debates about how and who should take it. It seemed like a big challenge and pretty scary for some teams, but not for us! We had our own ideas about how to approach the different challenges of such a system, and finally after a long wait we got the opportunity to officially take on the project.
This post is an adaptation of my original post in in Glovo’s Medium blog: Customer Segmentation at Glovo Part 1.
Business context
Glovo orchestrates a variety of discount campaigns. Before the Segmentation Service, these campaigns targeted our entire customer base, regardless of individual customer behavior or preference. For Glovo and its partners, this was highly inefficient in terms of budget and ROI, limiting customer acquisition, retention, and overall customer experience. We didn’t have a system capable of classifying the most appropriate discount campaign for each kind of customer. For example:
- users who never ordered from a specific store
- users who haven’t ordered in the last month
- users who order recurrently
We began by providing a definition of this new concept called “Segmentation” and a new bounded context called “Segments”; based on DDD concepts. Its responsibility was to “categorize customers based on different traits such as their profile, their order history, analytic events, and machine learning models”.
Scope for an MVP
We established the boundaries of our system and prioritized among the multiple stakeholders interested in different segment types. We needed a system capable of supporting most of their use cases. Therefore, we had to design the system properly with a focus on time to market, service response, scalability, and extensibility. Our first segment types were:
- New customers with 0 orders in certain stores
- Customers ordering recurrently from some stores
- Inactive customers who used to order in the past but they haven’t done so in a certain amount of time
Time to market was a hard constraint, so we committed to delivering a solution in only 3 months. We aimed to cover the first segmentation cases but also build an extensible system, capable of supporting different types of segments for the remaining and future use cases.
Challenges
Time-to-market
Our partners were in deep need and we didn’t want to lose their trust so we had to act fast and with vision.
Scaling calculations
We would start with only a few hundred segments but, shortly thereafter, would scale to hundreds of thousands of segments. A single segment calculation could involve millions of customers and hundreds of millions of order history items.
Fast-growing data volume
Not only would the number of segments grow, but so would our customer base, order history, and other new data source involved. We had to prepare to process big data.
Serving segments with high availability and low latency
The segments would be used in most customer flows to customize the customer’s journey, so latency was a very crucial constraint and couldn’t be hurt. In other words, we committed to a tight SLA, with an affordable latency of p99 <= 50 milliseconds and availability >= 99.99%
Offline data vs Real-time data
Processing and serving terabytes of data to millions of users was challenging, but having this system working with real-time data was even more difficult. Luckily, not all segments required live data, and they could work just fine with eventually consistent segments, with a few minutes delay for updates. We used this to our advantage and started by tackling the use cases that could be near real-time. This simplified our first version of the system, postponing the implementation of those other segments for later.
Integration
How would these new customer segments be served to the whole Glovo ecosystem in a standardized way? We aimed for a solution that would be agnostic of the calling domain, but at the same time provide the required flexibility to serve each domain’s needs. Also, we wanted to integrate other components in the system that could possibly calculate other types of segments in their own way. For example, some Machine Learning models were already generating some kinds of customer segments, and we should be able to feed their results into our service just as a new type of segment.
Cost
Cost doesn’t come only from marketing campaigns, but also from tech, ranging from infrastructure and maintenance costs to new feature development. The cost of the solution cannot be more expensive than the cost of losing partners or unhappy customers. For this project, we aimed for a solution that was cost-effective yet maintainable, reasonably extensible to cover our main use cases in the cluster, and easily evolvable to support new use cases. This allowed us to shorten the delivery of an MVP, meeting our strict time-to-market constraint.
Customer UX validation
We used Feature toggles and AB testing:
- To customize each customer’s UX and applicable discounts
- To compare the Return on Investment (ROI) against non-segmented discount campaigns
- To assess the cost of customer acquisition, flexibility of defining new configurations, and scalability
High-level architecture
Our segmentations component would serve data to the rest of the Glovo ecosystem like this:
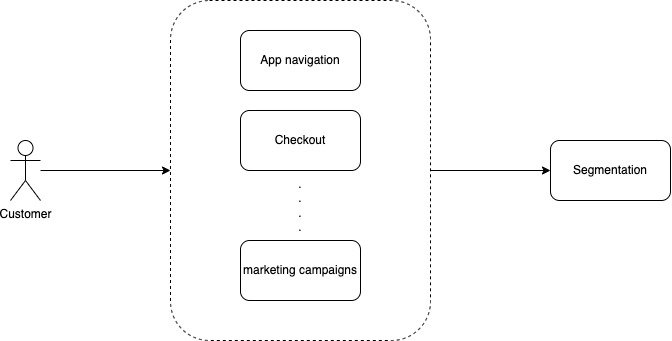
We assessed the nonfunctional requirements and quickly realized that the segment’s calculation flows were quite different from the serving data; especially in terms of data volume and required latency. This led us to split calculations and reads into two different components on the architectural level. The Segments Core would be responsible for calculating the segments by processing vast and diverse types of data. The Segment Store would be responsible for serving the calculated segments to the rest of the system, with high availability and low latency. Having these two separate components would also allow us to choose the appropriate technologies for each task.
If you are interested to know what the architecture looks like check part 2 “Segmentation service zoom in”!
Comments